Python 動くグラフ (2021 MLB American League / Home Run 争い)

前回、pybaseball / MLBデータ分析ライブラリ にて、MLBの触れるデータを確認した。
今回は試しに、2021年 MLB アメリカンリーグ 本塁打争いのデータを確認してみた。
まあ、以下のようなのが作ってみたかったのです。
備忘録として流れを記載
pybaseballライブラリを使ってMLBのStatcastデータを取得する。
!pip install pybaseball
from pybaseball import statcast
df = statcast(start_dt='2021-04-01', end_dt='2021-12-31')Pythonを使う。pybaseballライブラリを使って、MLBのStatcastデータを取得する。
pip installコマンドを使ってpybaseballライブラリをインストール。
ライブラリがインストールされたら、statcast()関数を使って、指定した期間のStatcastデータを取得。この場合、2021年4月1日から2021年12月31日の期間のデータをリクエスト。この関数は、指定した期間のStatcastデータを含むPandasのデータフレームを返す。
注意することとして、pybaseballが提供するStatcastデータは、レギュラーシーズンのゲームのみを含む。プレーオフやオールスターゲームのデータは含まれない。
3月のデータがあったのでオープン戦の結果は入ってそう。
大谷のホームラン数で確認
player_hr = df[(df['batter'] == 660271) & (df['events'] == 'home_run')]
print(len(player_hr))このコードでは、Pandasデータフレームdfから打者IDが660271で、イベントがホームランのデータを抽出している。それらのデータを含む新しいデータフレームplayer_hrが作成される。
ID 660271 は大谷です
https://baseballsavant.mlb.com/savant-player/shohei-ohtani-660271
URLにIDが載ってます
その後、len()関数を使ってplayer_hrデータフレームの行数(すなわち、ホームランの発生した試合数)をカウントしている。その結果をprint()関数を使って出力。
結果は、46
2021年 大谷のホームラン数と一致。OK

大谷のホームランをグラフ化
player_hr = df[(df['batter'] == 660271) & (df['events'] == 'home_run')]
player_hr_by_date = player_hr.groupby('game_date').size()このコードでは、まずPandasデータフレームdfから、打者IDが660271で、イベントがホームランのデータを抽出。それらのデータを含む新しいデータフレームplayer_hrが作成される。
次に、groupby()メソッドを使って、player_hrデータフレームをゲーム日ごとにグループ化。size()関数を使って、各ゲーム日ごとの行数(すなわち、ホームランの発生した試合数)をカウント。その結果を、新しいデータフレームplayer_hr_by_dateに格納。
これで、ゲーム日ごとにホームランの発生した試合数が、新しいデータフレームplayer_hr_by_dateに格納される。
import matplotlib.pyplot as plt
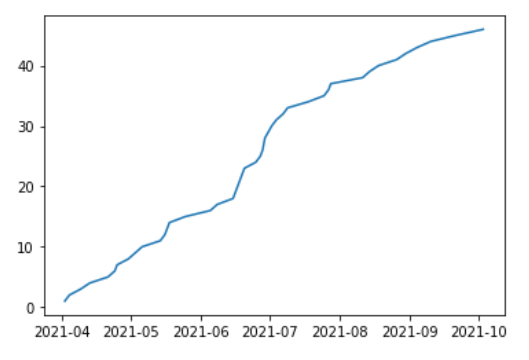
plt.plot(player_hr_by_date.cumsum())
plt.show()
このコードでは、Matplotlibライブラリを使って、データフレームplayer_hr_by_dateのグラフを描画。
plot()関数を使ってデータフレームのデータを折れ線グラフとして描画。また、cumsum()関数を使って、各ゲーム日ごとのホームランの発生した試合数を累積和にしている。
最後に、show()関数を使って、グラフを表示。
このコードを実行すると、指定した期間内で、各ゲーム日ごとにホームランを打った試合数を累積和としたグラフが描画される。
選手を追加
2021年ホームラン数Top8に入った選手のデータを追加してみました。
| ID | Player |
|---|---|
| 660271 | Shohei Ohtani |
| 665489 | Vladimir Guerrero |
| 521692 | Salvador Pérez |
| 543760 | Marcus Semien |
| 571745 | Mitch Haniger |
| 592450 | Aaron Judge |
| 664040 | Brandon Lowe |
| 621566 | Matt Olson |
# 選手のID
player_ids = [660271, 665489, 521692, 543760, 571745, 592450, 664040, 621566]
# 選手ごとのホームラン数を日付ごとに集計
player_hrs = {}
for player_id in player_ids:
player_hr = df[(df['batter'] == player_id) & (df['events'] == 'home_run')]
player_hrs[player_id] = player_hr.groupby('game_date').size()
このコードでは複数の選手のIDを含むリストplayer_idsを定義している。次にこのリストを使って選手ごとにホームランの発生した試合数を日付ごとに集計。
for文を使ってplayer_idsリストを一つずつ取り出している。取り出した選手IDを使って、Pandasデータフレームdfから打者ID、イベントがホームランのデータを抽出。それらのデータを含む新しいデータフレームを作成。
次に、groupby()メソッドを使ってこのデータフレームをゲーム日ごとにグループ化。そしてsize()関数を使って各ゲーム日ごとの行数(すなわち、ホームランの発生した試合数)をカウント。その結果を辞書player_hrsのキーが選手のID、値がゲーム日ごとのホームランの発生した試合数を持つSeriresオブジェクトとして格納。
実行すると辞書player_hrsには、各選手のゲーム日ごとのホームランの発生した試合数がSeriresオブジェクトとして格納。
import matplotlib.pyplot as plt
# プロットを重ねるため、プロットを初期化
plt.clf()
# 選手ごとにプロット
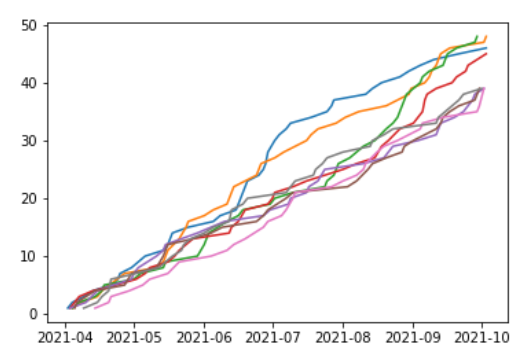
for player_id, player_hr in player_hrs.items():
plt.plot(player_hr.cumsum())
plt.show()このコードでは、Matplotlibライブラリを使って、複数の選手のゲーム日ごとのホームランの発生した試合数をプロットしている。
まずclf()関数を使ってプロットを初期化。これにより前回のプロットが重なることを防ぐ。
次に、for文を使って辞書player_hrsから選手のIDとその選手のゲーム日ごとのホームランの発生した試合数を取り出している。そして、plot()関数を使ってこのデータを折れ線グラフとして描画している。またcumsum()関数を使って各ゲーム日ごとのホームランの発生した試合数を累積和にして描画している。
最後にshow()関数を使ってプロットを表示。
このコードを実行すると、複数の選手のゲーム日ごとにホームランを打った試合数を累積和としたグラフが重ねて描画される。
グラフにレジェンドを追加するのは、以下です
plt.legend()
累積値のデータを作成
csvファイルは試しに実行しただけ。
import pandas as pd
# データフレームを作成
df_hrs = pd.DataFrame(player_hrs)
# df_hrs データフレームを累積値にする
df_hrs_cumsum = df_hrs.cumsum()
# CSV ファイルに保存
df_hrs_cumsum.to_csv('player_hrs_cumsum.csv', index=True)
このコードでは辞書player_hrsからPandasデータフレームを作成。辞書のキーがカラム名、値がデータとして、新しいデータフレームdf_hrsを作成。
次に、データフレームdf_hrsを累積値にして、新しいデータフレームdf_hrs_cumsumを作成。
最後にデータフレームdf_hrs_cumsumをCSVファイルplayer_hrs_cumsum.csvとして保存。引数index=Trueを指定することで、データフレームのインデックスも保存される。
このコードを実行すると、カラム名が選手のID、行名がゲーム日を表すインデックスを持つ、CSVファイルが作成される。各カラムには、その選手のゲーム日ごとにホームランを打った試合数を累積値として保存される。
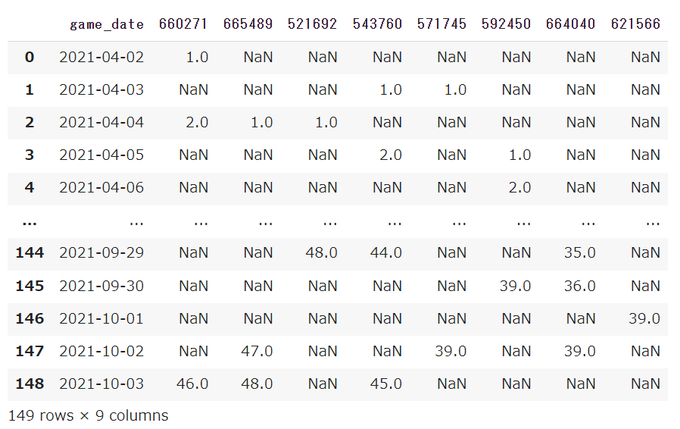
import pandas as pd
# CSV ファイルを読み込む
df = pd.read_csv('player_hrs_cumsum.csv')
# データフレームを表示する
df
このコードでは、Pandasのread_csv()関数を使ってCSVファイルplayer_hrs_cumsum.csvを読み込んでいる。この関数はCSVファイルをPandasデータフレームとして読み込むことができる。
読み込んだデータフレームを行名がゲーム日を表すインデックスを持つ、カラム名が選手のIDを持つデータフレームとして、変数dfに格納。
最後に、変数dfを表示している。これにより、カラム名が選手のID、行名がゲーム日を表すインデックスを持つ、CSVファイルを読み込んだデータフレームが表示される。
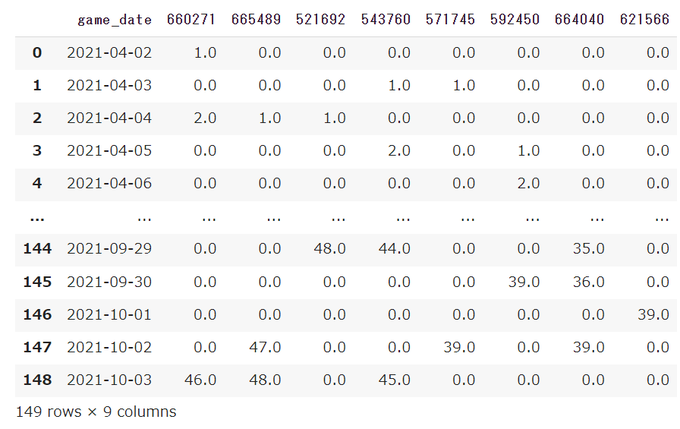
NaNを0へ
df = df.fillna(0)
# データフレームを表示する
dfこのコードでは、Pandasのfillna()メソッドを使ってデータフレームdfのNaN(Not a Number)を指定した値で埋めている。
fillna()メソッドは、データフレームのNaNを任意の値で埋めることができるメソッド。引数に埋める値を指定できる。
このコードでは、fillna()メソッドを使ってデータフレームdfのNaNを0で埋めている。これによりデータフレームdf内に含まれるすべてのNaNが0で埋められる。
このコードを実行すると、データフレームdfのすべてのNaNが0で埋められる。
game_dateカラムを日付型に変換
する意味なかったかも、むしろ不要
df["game_date"] = pd.to_datetime(df["game_date"])
df.set_index("game_date", inplace=True)
このコードでは、Pandasのto_datetime()関数を使ってデータフレームdfのgame_dateカラムを日付型に変換している。
to_datetime()関数は、日付文字列やタイムスタンプを日付型のデータに変換することができる関数。引数に変換したい日付文字列やタイムスタンプを指定する。
このコードでは、to_datetime()関数を使ってデータフレームdfのgame_dateカラムを日付型に変換している。これによりgame_dateカラムは日付型のデータになる。
次に、Pandasのset_index()メソッドを使ってデータフレームdfのインデックスをgame_dateカラムに設定している。引数inplace=Trueを指定することでデータフレームを直接書き換えることができる。
このコードを実行するとデータフレームdfのgame_dateカラムが日付型に変換され、データフレームdfのインデックスがgame_dateカラムに設定される。
これにより、データフレームdfはゲーム日を表す日付型のインデックスを持つカラム名が選手のIDを持つデータフレームになる。
前日の値を引き継ぐようにした
4/1からでも良かったけど。過剰に行った
df_after_3_15 = df[df.index >= "2021-03-15"]
# 各列を取得する
columns = df_after_3_15.columns
# 各列ごとに処理を行う
for column in columns:
values = df_after_3_15[column]
for i in range(1, len(values)):
if values[i] == 0:
values[i] = values[i - 1]
# 変更したデータを、元のデータフレームに戻す
df_after_3_15[column] = values
このコードでは、データフレームdfから2021年3月15日以降のデータを取り出して新しいデータフレームdf_after_3_15を作成している。
次に、データフレームdf_after_3_15の各カラムを取り出しそれぞれに対して処理を行っている。
処理は、各カラムのデータを取り出しそれを1つずつ繰り返し処理している。1番目のデータは何もしないが、2番目以降のデータは前のデータと同じ値に更新している。
これにより、2番目以降のデータが前のデータと同じ値に更新される。
最後に、変更したデータを元のデータフレームdf_after_3_15に戻している。
このコードを実行するとデータフレームdf_after_3_15の各カラムの2番目以降のデータが前のデータと同じ値に更新される。
print(df_after_3_15)
カラム名を変更
print(df_after_3_15.columns)
Index(['660271', '665489', '521692', '543760', '571745', '592450', '664040', '621566'], dtype='object')
print(df_after_3_15.columns)で、現在のカラム名を表示した
df_after_3_15.columns = ['Shohei Ohtani', 'Vladimir Guerrero Jr.', 'Salvador Pérez', 'Marcus Semien', 'Mitch Haniger', 'Aaron Judge', 'Brandon Lowe', 'Matt Olson']
df_after_3_15.columnsに新しいカラム名のリストを代入することでカラム名を変更
print(df_after_3_15.columns)
Index(['Shohei Ohtani', 'Vladimir Guerrero Jr.', 'Salvador Pérez', 'Marcus Semien', 'Mitch Haniger', 'Aaron Judge', 'Brandon Lowe', 'Matt Olson'], dtype='object')
これでOK
Bar Chart Race 作成
!pip install bar_chart_race
import pandas as pd
import bar_chart_race as bcr
bcr.bar_chart_race(df=df_after_3_15, n_bars=8)
追加確認
4/1に0追加
import numpy as np
import pandas as pd
# 全選手に0というデータを追加する
new_row = np.zeros(8)
# データフレームに追加する
df_after_3_15.loc['2021-04-01'] = new_row
# インデックスを日付に変換する
df_after_3_15.index = pd.to_datetime(df_after_3_15.index)
# データフレームを昇順に並べ替える
df_after_3_15.sort_index(inplace=True)
# 追加されたことを確認する
print(df_after_3_15)
このコードは、すべての値が0に設定された新しい行をdf_after_3_15データフレームに追加する。新しい行はインデックス'2021-04-01'に追加される。
次に、pandasライブラリのto_datetime関数を使用して、データフレームのインデックスを日付型オブジェクトに変換。
最後に、sort_index関数を使用してデータフレームをインデックスの昇順で並び替え。inplaceパラメータがTrueに設定されているため、データフレームはインプレースで並び替えられ、元のデータフレームが修正される。
このコードを実行すると、df_after_3_15データフレームにはインデックス'2021-04-01'に新しい行が含まれ、インデックスの昇順で並び替えられる。
グラフ
import matplotlib.pyplot as plt
# 折れ線グラフを作成する
plt.plot(df_after_3_15)
# グラフにレジェンドを追加する
plt.legend(df_after_3_15.columns)
# グラフを表示する
plt.show()
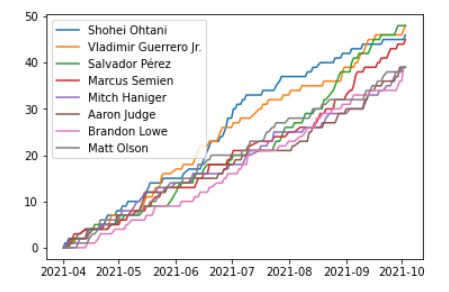
このコードは、matplotlib.pyplotライブラリのplot関数を使用して、df_after_3_15データフレームのデータを折れ線グラフで表示。
その後、legend関数を使用してデータフレームの列名をラベルとしてプロットに凡例を追加する。
最後に、show関数を使用してプロットを表示。
このコードを実行すると、df_after_3_15データフレームのデータを示す折れ線グラフと列名を示す凡例が表示される。
データ追加後、Bar Chat Race 反応しなかった。