NFTgeek NFTトランザクションcsv ダウンロード自動化 : PythonとSeleniumを使用してChromeとEdgeから自動でファイルをダウンロード

NFTgeek NFTトランザクションcsv ダウンロード自動化 : PythonとSeleniumを使用してChromeとEdgeから自動でファイルをダウンロード
NFTgeekからcsvファイル、何かと面倒なので自動化
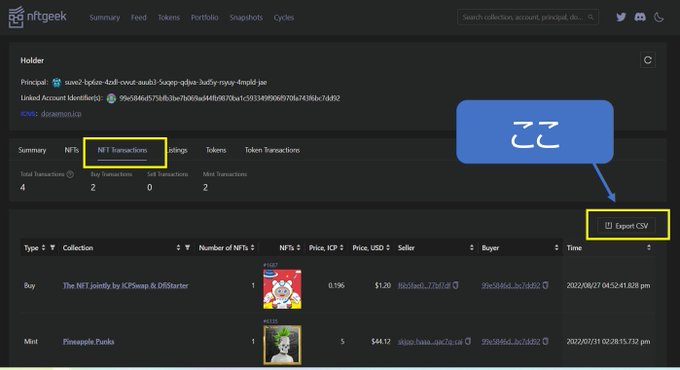
これから、記載のコードに、各々のtransactionページのURLを書き込めば良い感じ
はじめに
データ収集や自動化テストなど、Webサイトから定期的にファイルをダウンロードする必要がある場面は少なくありません。手動でのダウンロードは時間がかかる上に、繰り返し作業はエラーを引き起こしやすくなります。このような問題を解決するために、PythonとSeleniumを使用して、Google ChromeとMicrosoft Edgeの両方でファイルを自動でダウンロードする方法を紹介します。
必要なツールとセットアップ
この自動化スクリプトを実行する前に、以下のツールが必要です。
- Python: プログラミング言語
- Selenium: Webブラウジングの自動化を支援するツール
PythonとSeleniumのインストール
Pythonは公式ウェブサイトからダウンロードできます。インストール後、以下のコマンドを使用してSeleniumをインストールしてください。
pip install selenium
WebDriverのダウンロード
Seleniumでブラウザを自動操作するには、それぞれのブラウザ用のWebDriverが必要です。
- Chrome: ChromeDriver
- Edge: Microsoft Edge Driver
ダウンロード後、WebDriverを任意のディレクトリに配置し、そのパスを記録しておきます。
スクリプトの説明
共通のセットアップ
まず、必要なモジュールをインポートし、ダウンロードディレクトリを設定します。このディレクトリはダウンロードしたファイルを保存する場所です。
import os
import datetime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 保存先ディレクトリの設定
date_folder = datetime.datetime.now().strftime("%Y-%m-%d")
downloads_path = "YOUR_DOWNLOAD_PATH" # ダウンロードするフォルダのパスを設定
save_folder = os.path.join(downloads_path, date_folder)
if not os.path.exists(save_folder):
os.makedirs(save_folder)
Chromeでのダウンロード自動化
Google Chromeを使用してファイルを自動ダウンロードするには、chromedriver.exeのパスを指定して、Chrome WebDriverを設定します。
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options as ChromeOptions
# ChromeDriverのパスを設定
driver_path = r'YOUR_CHROMEDRIVER_PATH'
# Chromeオプション設定
chrome_options = ChromeOptions()
chrome_options.add_experimental_option("prefs", {
"download.default_directory": save_folder,
"download.prompt_for_download": False,
"safebrowsing.enabled": True
})
# WebDriverのセットアップ
service = ChromeService(executable_path=driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
Edgeでのダウンロード自動化
Microsoft Edgeを使用してファイルを自動ダウンロードするには、msedgedriver.exeのパスを指定して、Edge WebDriverを設定します。
from selenium.webdriver.edge.service import Service as EdgeService
from selenium.webdriver.edge.options import Options as EdgeOptions
# EdgeDriverのパスを指定
driver_path = r'YOUR_EDGEDRIVER_PATH'
# Edgeオプション設定
edge_options = EdgeOptions()
edge_options.use_chromium = True
edge_options.add_experimental_option("prefs", {
"download.default_directory": save_folder,
"download.prompt_for_download
": False,
"safebrowsing.enabled": True
})
# EdgeServiceを使用してWebDriverのセットアップ
service = EdgeService(executable_path=driver_path)
driver = webdriver.Edge(service=service, options=edge_options)
ダウンロードプロセス
指定されたURLリストから「Export CSV」ボタンをクリックしてCSVファイルをダウンロードし、特定のディレクトリに自動的に保存し、各ダウンロードがしっかりと完了するまで待機する処理は、ブラウザに関わらず共通です。以下は、そのプロセスを実行するコードの一部です。
俺の捨てアドレスを載せておこう
# ダウンロードするページのURLリスト
urls = [
"https://t5t44-naaaa-aaaah-qcutq-cai.raw.ic0.app/holder/797d77d13274e73ca766bef21ec9650739ef0ab840211925d05186fb848c417f/transactions",
"https://t5t44-naaaa-aaaah-qcutq-cai.raw.ic0.app/holder/bb5b11122334a09fc52f50ac4f10ab60e76e7129d0f753ceaa6dfdc484987b16/transactions"
]
# 他のURLを追加
for url in urls:
driver.get(url)
# ページが完全にロードされるのを確実に待つ
WebDriverWait(driver, 30).until(EC.visibility_of_element_located((By.TAG_NAME, 'body')))
# ページ表示後に追加で待機
time.sleep(5)
try:
export_button = WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, "//span[contains(text(),'Export CSV')]"))
)
export_button.click()
# ダウンロード完了を待つ
wait_for_downloads(save_folder)
# ダウンロードの安定性を向上させるために追加の待機
time.sleep(10)
except Exception as e:
print(f"Error downloading from {url}: {e}")
driver.quit()
完全なコード
Google Chrome用の完全なスクリプト
import os
import datetime
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options as ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def wait_for_downloads(directory, timeout=300):
end_time = time.time() + timeout
while True:
is_downloading = False
for filename in os.listdir(directory):
if filename.endswith('.tmp') or filename.endswith('.crdownload'):
is_downloading = True
break
if not is_downloading or time.time() > end_time:
break
time.sleep(1)
if is_downloading:
print("ダウンロードがタイムアウトに達しました。")
else:
print("すべてのダウンロードが完了しました。")
driver_path = r'YOUR_CHROMEDRIVER_PATH'
date_folder = datetime.datetime.now().strftime("%Y-%m-%d")
downloads_path = "YOUR_DOWNLOAD_PATH"
save_folder = os.path.join(downloads_path, date_folder)
if not os.path.exists(save_folder):
os.makedirs(save_folder)
chrome_options = ChromeOptions()
chrome_options.add_experimental_option("prefs", {
"download.default_directory": save_folder,
"download.prompt_for_download": False,
"safebrowsing.enabled": True
})
service = ChromeService(executable_path=driver_path)
driver = webdriver.Chrome(service=service, options=chrome_options)
urls = [
# URLリスト
]
for url in urls:
driver.get(url)
WebDriverWait(driver, 30).until(EC.visibility_of_element_located((By.TAG_NAME, 'body')))
time.sleep(5)
try:
export_button = WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, "//span[contains(text(),'Export CSV')]"))
)
export_button.click()
wait_for_downloads(save_folder)
time.sleep(10)
except Exception as e:
print(f"Error downloading from {url}: {e}")
driver.quit()
Microsoft Edge用の完全なスクリプト
import os
import datetime
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service as EdgeService
from selenium.webdriver.edge.options import Options as EdgeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def wait_for_downloads(directory, timeout=300):
# この関数の実装はChromeの場合と同じです
driver_path = r'C:\Users\----------\msedgedriver.exe'
date_folder = datetime.datetime.now().strftime("%Y-%m-%d")
downloads_path = "YOUR_DOWNLOAD_PATH"
save_folder = os.path.join(downloads_path, date_folder)
if not os.path.exists(save_folder):
os.makedirs(save_folder)
edge_options = EdgeOptions()
edge_options.use_chromium = True
edge_options.add_experimental_option("prefs", {
"download.default_directory": save_folder,
"download.prompt_for_download": False,
"safebrowsing.enabled": True
})
service = EdgeService(executable_path=driver_path)
driver = webdriver.Edge(service=service, options=edge_options)
urls = [
# URLリスト
]
for url in urls:
driver.get(url)
WebDriverWait(driver, 30).until(EC.visibility_of_element_located((By.TAG_NAME, 'body')))
time.sleep(5)
try:
export_button = WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, "//span[contains(text(),'Export CSV')]"))
)
export_button.click()
wait_for_downloads(save_folder)
time.sleep(10)
except Exception as e:
print(f"Error downloading from {url}: {e}")
driver.quit()
これらのスクリプトは、それぞれGoogle ChromeとMicrosoft Edgeでのファイルダウンロードを自動化します。YOUR_CHROMEDRIVER_PATHとYOUR_DOWNLOAD_PATHは、環境に合わせて適切なパスに置き換えてください。また、urlsリストにはダウンロードしたいファイルが存在するページのURLを追加してください。
という感じです。