Signate 練習問題 ID = 1 で試しに流れを実施

SHOGAKU
2年前
Signate 練習問題 ID = 1 で試しに流れを実施
備忘録
準備
!pip install signateGoogle ColabでSIGNATE APIを使う
from googleapiclient.discovery import build
import io, os
from googleapiclient.http import MediaIoBaseDownload
from google.colab import auth
auth.authenticate_user()
drive_service = build('drive', 'v3')
results = drive_service.files().list(
q="name = 'signate.json'", fields="files(id)").execute()
signate_api_key = results.get('files', [])
filename = "/root/.signate/signate.json"
os.makedirs(os.path.dirname(filename), exist_ok=True)
request = drive_service.files().get_media(fileId=signate_api_key[0]['id'])
fh = io.FileIO(filename, 'wb')
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
print("Download %d%%." % int(status.progress() * 100))
os.chmod(filename, 600)リスト確認
!signate list competitionId title closing prize submitters
--------------- -------------------------------------------------------------------------------- ---------- -------------- ------------
1 【練習問題】銀行の顧客ターゲティング - 6443
24 【練習問題】お弁当の需要予測 - 7824
27 【練習問題】Jリーグの観客動員数予測 - 1863
100 【練習問題】手書き文字認識 - Knowledge 283
102 【練習問題】タイタニックの生存予測 - Knowledge 1945
103 【練習問題】音楽ラベリング - Knowledge 115
104 【練習問題】スパムメール分類 - Knowledge 174
105 【練習問題】毒キノコの分類 - Knowledge 319
106 【練習問題】アワビの年齢予測 - Knowledge 418
107 【練習問題】国勢調査からの収入予測 - Knowledge 658
108 【練習問題】画像ラベリング(20種類) - Knowledge 289
112 【練習問題】ワインの品種の予測 - Knowledge 370
113 【練習問題】山火事の消失面積予測 - Knowledge 263
114 【練習問題】レンタル自転車の利用者数予測 - Knowledge 564
115 【練習問題】アヤメの分類 - Knowledge 462
116 【練習問題】活動センサーログからの動作予測 - Knowledge 69
118 【練習問題】テニスの試合結果の予測 - Knowledge 185
121 【練習問題】自動車の走行距離予測 - Knowledge 1754
122 【練習問題】自動車の評価 - Knowledge 363
123 【練習問題】オゾンレベルの分類 - Knowledge 85
124 【練習問題】ボットの判別 - Knowledge 361
125 【練習問題】ガラスの分類 - Knowledge 269
126 【練習問題】林型の分類 - Knowledge 73
127 【練習問題】ゲーム選手のリーグ分類 - Knowledge 98
128 【練習問題】ステンレス板の欠陥分類 - Knowledge 133
129 【練習問題】都市サイクルの燃料消費量予測 - Knowledge 306
130 【練習問題】天秤のバランス分類 - Knowledge 253
132 【練習問題】ネット広告のクリック予測 - Knowledge 161
133 【練習問題】画像ラベリング(10種類) - 405
135 【練習問題】ネット画像の分類 - 82
262 国立国会図書館の画像データレイアウト認識 2100-12-31 - 100
263 産業技術総合研究所 衛星画像分析コンテスト 2100-12-31 - 70
264 マイナビ × SIGNATE Student Cup 2019: 賃貸物件の家賃予測 2100-12-31 - 516
265 【練習問題】健診データによる肝疾患判定 - 668
266 【練習問題】民泊サービスの宿泊価格予測 - 713
267 海洋研究開発機構 熱帯低気圧(台風等)検出アルゴリズム作成 2100-12-31 - 32
268 オプト レコメンドエンジン作成 2100-12-31 62
269 アップル 引越し需要予測 2100-12-31 - 536
270 Weather Challenge:雲画像予測 2100-12-31 - 14
271 JR西日本 走行中の北陸新幹線車両台車部の着雪量予測 2100-12-31 - 33
288 Sansan 名刺の項目予測 2100-12-31 - 48
294 【練習問題】債務不履行リスクの低減 - 337
358 【練習問題】機械稼働音の異常検知 - 98
404 【練習問題】モノクロ顔画像の感情分類 - 139
406 【練習問題】鋳造製品の欠陥検出 - 279
409 【練習問題】株価の推移予測 - 245
565 SIGNATE Student Cup 2021春:楽曲のジャンル推定チャレンジ!! 2100-12-31 - 172
567 SIGNATE Student Cup 2021秋:オペレーション最適化に向けたシェアサイクルの利用予測 2100-12-31 - 121
595 医学論文の自動仕分けチャレンジ 2100-12-31 59
657 SUBARU 画像認識チャレンジ 2100-12-31 9
841 第1回 金融データ活用チャレンジ 2023-03-05 総額¥1,000,000 89
936 ブルーカーボン・ダイナミクスを可視化せよ! 2023-04-30 総額¥1,000,000 21練習問題 ID =1 を確認
!signate files --competition-id=1 fileId name title size updated_at
-------- ----------------- -------------- ------- -------------------
1 train.csv 学習用データ 2345067 2016-05-31 20:19:48
2 test.csv 評価用データ 1523536 2021-11-02 12:16:31
3 submit_sample.csv 応募用サンプル 205890 2016-05-31 20:20:59練習問題 ID =1 をダウンロード
!signate download --competition-id=1 submit_sample.csv
test.csv
train.csv
Download completed.中身を確認
import pandas as pd
submit_sample = pd.read_csv('submit_sample.csv')
test = pd.read_csv('test.csv')
train = pd.read_csv('train.csv')
print(submit_sample.head())
print(test.head())
print(train.head()) 1 0.236
0 2 0.128
1 3 0.903
2 4 0.782
3 5 0.597
4 6 0.555
id age job marital education default balance housing loan \
0 1 30 management single tertiary no 1028 no no
1 2 39 self-employed single tertiary no 426 no no
2 3 38 technician single tertiary no -572 yes yes
3 4 34 technician single secondary no -476 yes no
4 5 37 entrepreneur married primary no 62 no no
contact day month duration campaign pdays previous poutcome
0 cellular 4 feb 1294 2 -1 0 unknown
1 unknown 18 jun 1029 1 -1 0 unknown
2 unknown 5 jun 26 24 -1 0 unknown
3 unknown 27 may 92 4 -1 0 unknown
4 cellular 31 jul 404 2 -1 0 unknown
id age job marital education default balance housing loan \
0 1 39 blue-collar married secondary no 1756 yes no
1 2 51 entrepreneur married primary no 1443 no no
2 3 36 management single tertiary no 436 no no
3 4 63 retired married secondary no 474 no no
4 5 31 management single tertiary no 354 no no
contact day month duration campaign pdays previous poutcome y
0 cellular 3 apr 939 1 -1 0 unknown 1
1 cellular 18 feb 172 10 -1 0 unknown 1
2 cellular 13 apr 567 1 595 2 failure 1
3 cellular 25 jan 423 1 -1 0 unknown 1
4 cellular 30 apr 502 1 9 2 success 1 中身を確認2
print(submit_sample.shape)
print(test.shape)
print(train.shape)
(18082, 2)
(18083, 17)
(27128, 18)Dataframeから欠損値のある行を取得
# Dataframeから欠損値のある行を取得
missing_rows = train[train.isnull().any(axis=1)]
print(missing_rows)
Empty DataFrame
Columns: [id, age, job, marital, education, default, balance, housing, loan, contact, day, month, duration, campaign, pdays, previous, poutcome, y]
Index: []欠損値がある行の数をカウント
# 欠損値がある行の数をカウント
missing_row_count = train.isnull().sum().sum()
print(missing_row_count)0相関係数を算出
import numpy as np
# 相関係数を算出
corr = train.corr()
# 相関係数の高い特徴量を選択
high_corr_features = corr[(corr['y'] > 0.1) | (corr['y'] < -0.1)].index
X = train[high_corr_features].drop(columns='y')
corr
id age balance day duration campaign pdays previous y
id 1.000000 -0.005716 -0.000484 0.002974 0.002705 0.016867 -0.004526 -0.005425 -0.003555
age -0.005716 1.000000 0.095343 -0.008518 -0.005309 -0.001340 -0.025272 0.002946 0.020892
balance -0.000484 0.095343 1.000000 0.002067 0.019923 -0.016295 0.003613 0.012483 0.045826
day 0.002974 -0.008518 0.002067 1.000000 -0.032453 0.164880 -0.096889 -0.050009 -0.031058
duration 0.002705 -0.005309 0.019923 -0.032453 1.000000 -0.087771 0.002030 0.002489 0.401390
campaign 0.016867 -0.001340 -0.016295 0.164880 -0.087771 1.000000 -0.086220 -0.031557 -0.076118
pdays -0.004526 -0.025272 0.003613 -0.096889 0.002030 -0.086220 1.000000 0.421606 0.100930
previous -0.005425 0.002946 0.012483 -0.050009 0.002489 -0.031557 0.421606 1.000000 0.083825
y -0.003555 0.020892 0.045826 -0.031058 0.401390 -0.076118 0.100930 0.083825 1.000000job列をダミー変数に変換
# job列をダミー変数に変換
X = pd.get_dummies(train, columns=['job'])
# job列を確認
print(X.columns)
Index(['id', 'age', 'marital', 'education', 'default', 'balance', 'housing',
'loan', 'contact', 'day', 'month', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'y', 'job_admin.', 'job_blue-collar',
'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired',
'job_self-employed', 'job_services', 'job_student', 'job_technician',
'job_unemployed', 'job_unknown'],
dtype='object')他もダミー変数に変換
X = pd.get_dummies(train, columns=['job','marital','education','housing','loan','contact','month','poutcome'])
print(X.columns)
Index(['id', 'age', 'default', 'balance', 'day', 'duration', 'campaign',
'pdays', 'previous', 'y', 'job_admin.', 'job_blue-collar',
'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired',
'job_self-employed', 'job_services', 'job_student', 'job_technician',
'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married',
'marital_single', 'education_primary', 'education_secondary',
'education_tertiary', 'education_unknown', 'housing_no', 'housing_yes',
'loan_no', 'loan_yes', 'contact_cellular', 'contact_telephone',
'contact_unknown', 'month_apr', 'month_aug', 'month_dec', 'month_feb',
'month_jan', 'month_jul', 'month_jun', 'month_mar', 'month_may',
'month_nov', 'month_oct', 'month_sep', 'poutcome_failure',
'poutcome_other', 'poutcome_success', 'poutcome_unknown'],
dtype='object')yとの相関を確認
# yとの相関を確認
X['y'] = train['y']
corr = X.corr()
print(corr['y'].sort_values(ascending=False))
y 1.000000
duration 0.401390
poutcome_success 0.303472
housing_no 0.140307
contact_cellular 0.137388
month_mar 0.128539
month_oct 0.127828
month_sep 0.120275
pdays 0.100930
previous 0.083825
job_student 0.081543
month_dec 0.081025
job_retired 0.077087
loan_no 0.065630
marital_single 0.062806
month_apr 0.061386
education_tertiary 0.059895
balance 0.045826
month_feb 0.035408
job_management 0.030974
job_unemployed 0.025624
poutcome_other 0.023954
age 0.020892
poutcome_failure 0.016025
contact_telephone 0.015491
education_unknown 0.011429
job_admin. 0.008689
job_self-employed 0.004024
marital_divorced 0.002381
month_aug -0.003338
id -0.003555
job_unknown -0.004015
month_jan -0.009886
job_technician -0.014642
job_housemaid -0.014899
month_nov -0.015932
job_entrepreneur -0.017122
month_jun -0.018077
job_services -0.027410
education_secondary -0.028497
day -0.031058
month_jul -0.034430
education_primary -0.042550
marital_married -0.059377
loan_yes -0.065630
job_blue-collar -0.071971
campaign -0.076118
month_may -0.101259
housing_yes -0.140307
contact_unknown -0.152880
poutcome_unknown -0.164607
Name: y, dtype: float64ロジスティック回帰モデルを作成し学習
import matplotlib.pyplot as plt
# 相関が高い特徴量を選択します。
X = train[['duration','pdays','previous']]
# ラベル(y)を定義します。
y = train['y']
# 学習用とテスト用データに分割します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 特徴量を正規化します。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 使用したいアルゴリズムを選択し、モデルを作成します。
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state=0)
classifier.fit(X_train, y_train)LogisticRegression(random_state=0)特徴量の選択、データの前処理、ロジスティック回帰モデルの作成、評価
# 作成したモデルを使用して、テストデータを予測します
y_pred = classifier.predict(X_test)
# 予測結果を評価するために、混合行列を作成します。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
# 結果を可視化するために、ROC曲線を作成します。
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
logit_roc_auc = roc_auc_score(y_test, classifier.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, classifier.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.savefig('Log_ROC')
plt.show()
#このように、特徴量の選択、データの前処理、モデルの作成、評価を行うことで、顧客に対するターゲット変数(y)を予測することができます。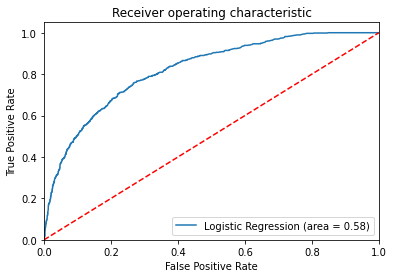
[[4701 70]
[ 540 115]]
作成した学習済みのモデルを使用して、テストデータに対して予測を行う
# モデルテスト
# test.csvのデータを読み込み、特徴量を選択します。
test = pd.read_csv("test.csv")
X_test = test[['duration','pdays','previous']]
# test.csvのデータを正規化します。
X_test = sc.transform(X_test)
# 作成したモデルを使用して、test.csvのデータを予測します。
y_pred = classifier.predict(X_test)
# 予測結果を確認します。
print(y_pred)
# 予測結果をcsvに書き出します。
submission = pd.DataFrame({'y': y_pred})
[1 1 0 ... 0 0 0]予測された結果をcsvへ保存
# submission.csvを作成するために、必要なデータを取得します
submission_data = test[['id']]
submission_data['y'] = y_pred
# submission.csvを保存します
submission_data.to_csv('submission.csv', index=False)
Google Driveに保存する
# Google Driveに保存する
from google.colab import drive
drive.mount('/content/gdrive')
submission.to_csv('/content/gdrive/My Drive/submission.csv', index=False)
そして、そのままマニュアルで提出した。
まずは提出までを実施してみた。
コメント
いいね
投げ銭
最新順
人気順
コメント
いいね
投げ銭
最新順
人気順